|
OSHUN
beta
Arbitrary Order Spherical-Harmonic 1D-3P Vlasov-Fokker-Planck-Maxwell code
|


|
|
OSHUN
beta
Arbitrary Order Spherical-Harmonic 1D-3P Vlasov-Fokker-Planck-Maxwell code
|
|
#include <export.h>
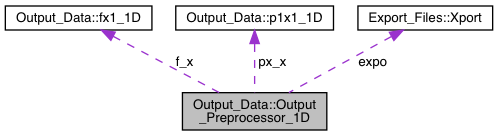
Public Member Functions | |
| Output_Preprocessor_1D (const Grid_Info &_grid, const vector< string > _oTags, string homedir="") | |
| void | operator() (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | distdump (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
Private Member Functions | |
| void | Ex (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | Ey (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | Ez (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | Bx (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | By (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | Bz (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | px (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | f0 (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | f10 (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | f11 (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | f20 (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | fl0 (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | n (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | T (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | Jx (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | Jy (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | Jz (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | Qx (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | Qy (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | Qz (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | vNx (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | vNy (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | vNz (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | Ux (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | Uy (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | Uz (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | Z (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | ni (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
| void | Ti (const State1D &Y, const Grid_Info &grid, const size_t tout, const Parallel_Environment_1D &PE) |
Private Attributes | |
| size_t | Nbc |
| Export_Files::Xport | expo |
| p1x1_1D | px_x |
| fx1_1D | f_x |
| vector< string > | oTags |
|
inline |
|
private |
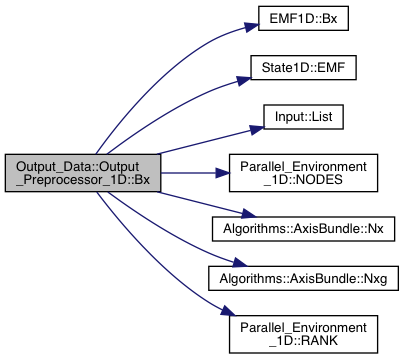
Definition at line 1571 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, EMF1D::Bx(), State1D::EMF(), Input::List(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), and Parallel_Environment_1D::RANK().
|
private |
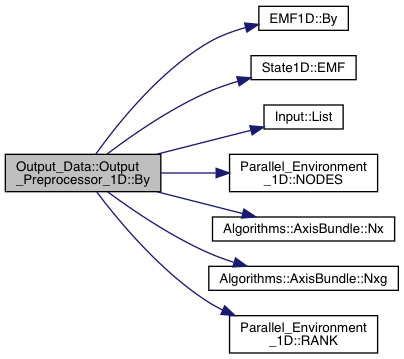
Definition at line 1621 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, EMF1D::By(), State1D::EMF(), Input::List(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), and Parallel_Environment_1D::RANK().
|
private |
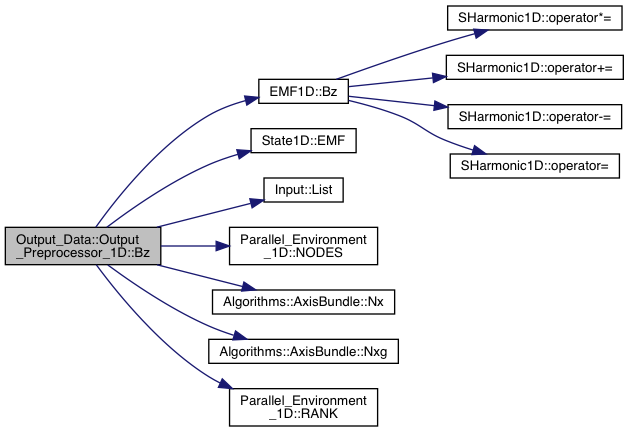
Definition at line 1671 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, EMF1D::Bz(), State1D::EMF(), Input::List(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), and Parallel_Environment_1D::RANK().
| void Output_Data::Output_Preprocessor_1D::distdump | ( | const State1D & | Y, |
| const Grid_Info & | grid, | ||
| const size_t | tout, | ||
| const Parallel_Environment_1D & | PE | ||
| ) |
Definition at line 1389 of file export.cpp.
References Input::List().
Referenced by main().


|
private |
Definition at line 1421 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, State1D::EMF(), EMF1D::Ex(), Input::List(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), and Parallel_Environment_1D::RANK().
|
private |
Definition at line 1471 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, State1D::EMF(), EMF1D::Ey(), Input::List(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), and Parallel_Environment_1D::RANK().
|
private |
Definition at line 1521 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, State1D::EMF(), EMF1D::Ez(), Input::List(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), and Parallel_Environment_1D::RANK().
|
private |
Definition at line 1862 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, State1D::DF(), Input::List(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), Parallel_Environment_1D::RANK(), and State1D::Species().
|
private |
Definition at line 1997 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, State1D::DF(), Input::List(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), Parallel_Environment_1D::RANK(), and State1D::Species().
|
private |
Definition at line 2068 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, State1D::DF(), Input::List(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), Parallel_Environment_1D::RANK(), and State1D::Species().
|
private |
Definition at line 2140 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, State1D::DF(), Input::List(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), Parallel_Environment_1D::RANK(), and State1D::Species().
|
private |
Definition at line 2212 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, State1D::DF(), DistFunc1D::l0(), Input::List(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), Parallel_Environment_1D::RANK(), and State1D::Species().
|
private |
Definition at line 2434 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, State1D::DF(), Input::List(), Algorithms::MakeCAxis(), DistFunc1D::mass(), Algorithms::moment(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), DistFunc1D::q(), Parallel_Environment_1D::RANK(), State1D::SH(), State1D::Species(), and vfloat().
|
private |
Definition at line 2493 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, State1D::DF(), Input::List(), Algorithms::MakeCAxis(), DistFunc1D::mass(), Algorithms::moment(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), DistFunc1D::q(), Parallel_Environment_1D::RANK(), State1D::SH(), State1D::Species(), and vfloat().
|
private |
Definition at line 2551 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, State1D::DF(), Input::List(), Algorithms::MakeCAxis(), DistFunc1D::mass(), Algorithms::moment(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), DistFunc1D::q(), Parallel_Environment_1D::RANK(), State1D::SH(), State1D::Species(), and vfloat_complex().
|
private |
Definition at line 2285 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, Input::List(), Algorithms::MakeCAxis(), Algorithms::moment(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), Parallel_Environment_1D::RANK(), State1D::SH(), State1D::Species(), and vfloat().
|
private |
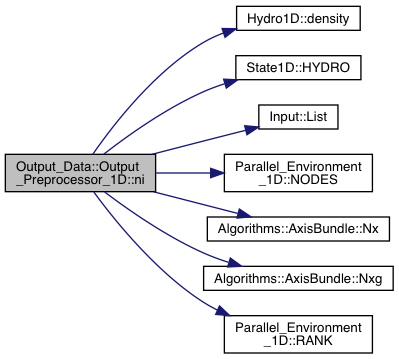
Definition at line 3305 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, Hydro1D::density(), State1D::HYDRO(), Input::List(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), and Parallel_Environment_1D::RANK().
| void Output_Data::Output_Preprocessor_1D::operator() | ( | const State1D & | Y, |
| const Grid_Info & | grid, | ||
| const size_t | tout, | ||
| const Parallel_Environment_1D & | PE | ||
| ) |
Definition at line 1277 of file export.cpp.
References Input::List().

|
private |
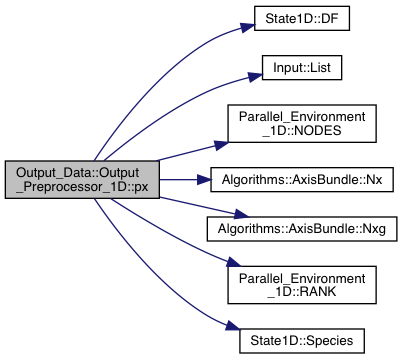
Definition at line 1720 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, State1D::DF(), Input::List(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), Parallel_Environment_1D::RANK(), and State1D::Species().
|
private |
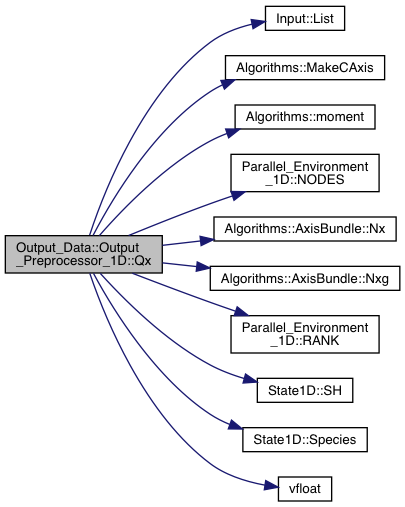
Definition at line 2607 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, Input::List(), Algorithms::MakeCAxis(), Algorithms::moment(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), Parallel_Environment_1D::RANK(), State1D::SH(), State1D::Species(), and vfloat().
|
private |
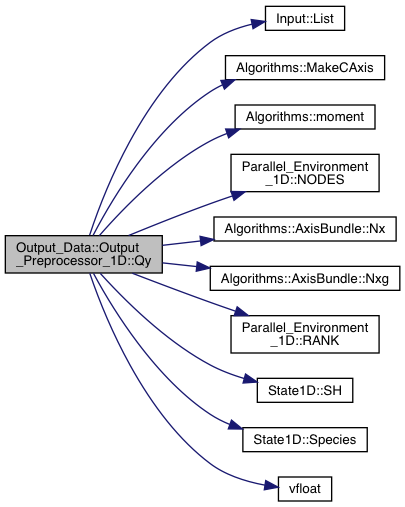
Definition at line 2713 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, Input::List(), Algorithms::MakeCAxis(), Algorithms::moment(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), Parallel_Environment_1D::RANK(), State1D::SH(), State1D::Species(), and vfloat().
|
private |
Definition at line 2819 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, Input::List(), Algorithms::MakeCAxis(), Algorithms::moment(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), Parallel_Environment_1D::RANK(), State1D::SH(), State1D::Species(), and vfloat_complex().
|
private |
Definition at line 2345 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, State1D::DF(), Input::List(), Algorithms::MakeCAxis(), DistFunc1D::mass(), Algorithms::moment(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), Parallel_Environment_1D::RANK(), State1D::SH(), State1D::Species(), and vfloat().
|
private |
Definition at line 3360 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, State1D::HYDRO(), Input::List(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), Parallel_Environment_1D::RANK(), and Hydro1D::temperature().
|
private |
Definition at line 3092 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, State1D::HYDRO(), Input::List(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), Parallel_Environment_1D::RANK(), and Hydro1D::vx().
|
private |
Definition at line 3144 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, State1D::HYDRO(), Input::List(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), Parallel_Environment_1D::RANK(), and Hydro1D::vy().
|
private |
Definition at line 3196 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, State1D::HYDRO(), Input::List(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), Parallel_Environment_1D::RANK(), and Hydro1D::vz().
|
private |
Definition at line 2926 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, Input::List(), Algorithms::MakeCAxis(), Algorithms::moment(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), Parallel_Environment_1D::RANK(), State1D::SH(), State1D::Species(), and vfloat().
|
private |
Definition at line 2985 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, Input::List(), Algorithms::MakeCAxis(), Algorithms::moment(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), Parallel_Environment_1D::RANK(), State1D::SH(), State1D::Species(), and vfloat().
|
private |
Definition at line 3037 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, Input::List(), Algorithms::MakeCAxis(), Algorithms::moment(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), Parallel_Environment_1D::RANK(), State1D::SH(), State1D::Species(), vfloat(), and vfloat_complex().
|
private |
Definition at line 3249 of file export.cpp.
References Grid_Info::axis, Input::Input_List::BoundaryCells, State1D::HYDRO(), Input::List(), Parallel_Environment_1D::NODES(), Algorithms::AxisBundle< T >::Nx(), Algorithms::AxisBundle< T >::Nxg(), Parallel_Environment_1D::RANK(), and Hydro1D::Z().
|
private |
|
private |
 1.8.13
1.8.13